第9回 次世代デジタルライブラリーの感想――日本語版Googleブックスの試み
小林昌樹(図書館情報学研究者)
■はじめに
前回予告では「索引の排列」について取り上げるつもりだったが、なんとびっくりGoogleブックスもどきβ版を日本の国立国会図書館(NDL)が公開したので、ここに紹介したい。こういった新奇DBにはいつも懐疑的なのだが、使ってみたら存外に「使える」ものだったので。
1.予備知識:情報粒度のレベル分け
十数年前から図書館情報学に入ってきた概念に「情報粒度」がある。どうやら鉱山学から情報学に入った言葉らしいのだが、それを出版物に当てはめると次のようになる。
・表1 粒度とツールの対応表
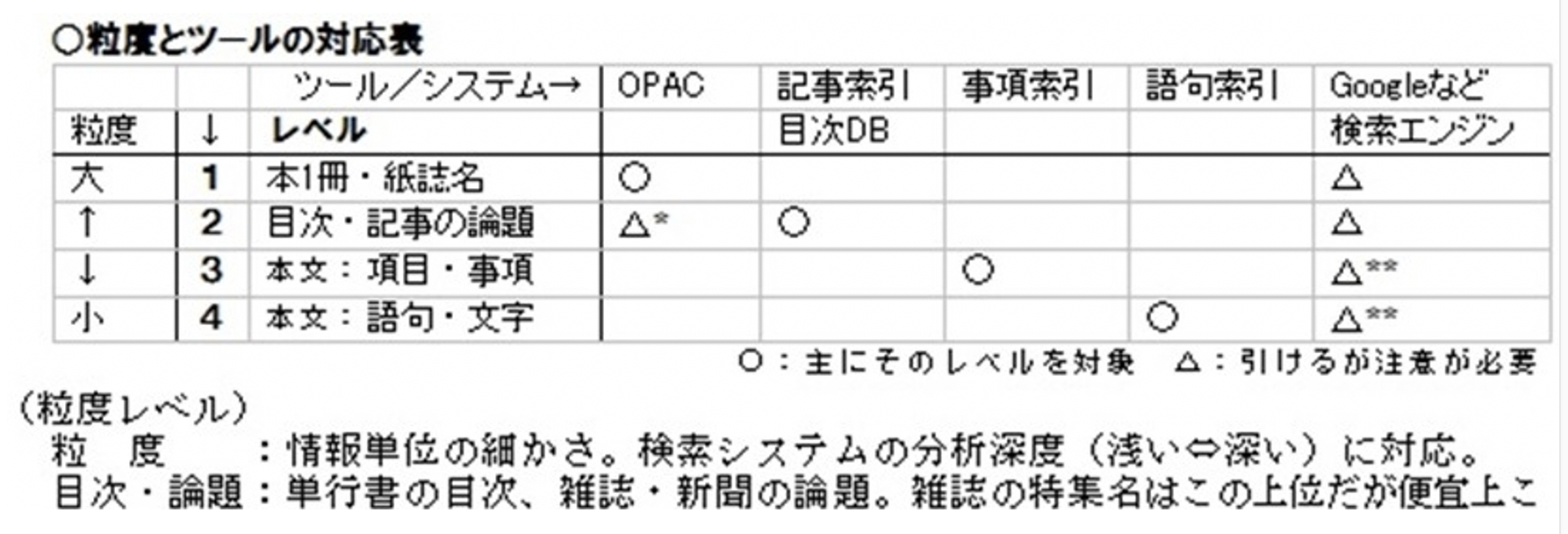
今まで、図書館のシステムは基本、レベル「1」の本や雑誌・新聞のタイトルレベル、せいぜい「2」の本の目次や雑誌の論題レベルまでしかフォローしてこなかった。レベル「3」「4」の本文レベルを、本をまたいで検索できるシステムやリストは非常に限られるので、全部憶えておくのがレファ司書の常道だった。まさかレファレンス担当で稲垣達郎ほか編 『明治文学全集 別巻 総索引』(筑摩書房, 1989)を知らぬものはおるまいね。近年では四庫全書の全文DBまた然りだが。
いまNDL人文リンク集の「全文データベース」の項を見ると、3つしかDBが挙がっていない。a. Googleブックス、b. J-STAGE(JST)、c. 青空文庫である。いま少しだけb. J-STAGEの全文検索機能を使ってみたところ、学術雑誌の記事ばかりで戦前のものはデータ量も少ないが、それなりに使えるDBになっている。
2.次デジはデジコレ全文データとは違うもの
さて、先々週だったか、今度私が出す研究誌『近代出版研究』に、ひっちゃきになって自分の論文を――自分のが一番後回しになっていた――書いている最中、ツイッターで次のDBが紹介されていた。
国会図書館の「次世代デジタルライブラリー」と名前がついているが、URLを見ると、略称は「ツギデジ」としたいらしい(長尾元館長流に言えば「ツギディジ」。長尾さんはさかんに「デジタルでなくディジタル」と言ってたそうな)。ということで私もツギデジと呼ぼう。
・次世代デジタルライブラリー https://lab.ndl.go.jp/service/tsugidigi/
で、このツギデジ、存外に使えることがわかった。なぜ「使える」のかというと、次のような事情らしい。
a. OCRシステムがNDLデジコレ全文とは異なるものを使っているらしい。
b. 連動して全文データもデジコレとは異なるデータが格納されているらしい。
c. インターフェイスのデザインがわかりやすい。
d. インターフェイス(というか検索機能)の不備を言ったたらすぐ対応してくれた。
おかげ様で、書いていた自分の論文の肝心な部分を書き換えることになった。逆に言うと、いまツギデジに関わる分野を研究している全研究者は必ず一度はこのDBを引くべき、とまで言ってよいだろう。
ツギデジでなくデジコレにも全文データ及びその検索システムは搭載されているが、悪いけれど使えなかった。レベル1、2、3は要約主題として主題検索に使えるが、4はただの本文なので、それを一緒に引けるのは、たとえ誤変換がなくてもノイズになる。レベルによって同じ文字列が違う意味を持つ*ってことは意外と知られていないのでは。
3.戦前期全文DBとして「使える」
画面をあけると「全文から検索する」「画像から検索する」の二択が出るが、画像検索のほうはデータ内容の問題からあまり使えないので、ここでは現状でも「使える」全文検索を紹介する。
・図1 次世代デジタルライブラリー(ツギデジ)
搭載データの収録年代及びジャンルなどの全体がいまひとつ説明を読んでもわからないのだが、開発中のDBにはよくあることで、検索結果から考えると、多くは明治期から戦争直後までの本で、文学や商業もそこそこある。ジャンルによっては昭和40年ごろまであるものもある。むかしのNDL風にいうと、帝国図書館本(旧函架)、NDC5版(赤坂本)、NDCの資料群(の一部)となろう。そのうち増えていくのだろう。
要するにツギデジは2022年2月現在ただいま、戦前期図書全文DBとして使えると言える。
おわり、ではちょっと説明不足かと思うので、実際の検索例を紹介してみる。
4.初出の調査で使える――「立ち読み」の初出例
ここ6,7年ほど、立ち読みの歴史について調べてきた。それは3月末に出る新雑誌『近代出版研究』に発表予定なのだが、その中で困っていたのは「立ち読み」の初出例である。定番の『日本国語大辞典』には戦後分しか用例がなく、いやしかし、戦前から立ち読み現象はあるわけで、行為でなく習俗としての立ち読み成立に、このフレーズ、体言形としての「立ち読み」の初出を見つけるのが肝要だった。
今まで日本語の全文検索DBで広く探せるものは、それこそ誤変換だらけのGoogleブックスを使うしかなく(連載第4回で説明)、たまたまツイッターで教えてもらった大正7(1918)年の用例が4年間ほど、私の中で最古のものでありつづけたのだが、絶対にもっとさかのぼれるはずと思ってきた。なにしろ、立ち読みの起源は明治20年代にあるので。それが、ツギデジのおかげであっさりと明治31(1899)年までさかのぼれた【図2】。
・図2 「立ち読み」の初出例――勝海舟座談(民友社、1899)座談は
※コマ番号をクリックすると、該当本文が表示され、どこかタグ(水色)も表示される(表示されないことも)。

5.チップスいろいろ
・文字の正規化
NDLの検索システムは、閲覧部門の独自開発(例:リサーチ・ナビ)を除いておおむね「文字の正規化」を行っているので、新漢字でも旧漢字も探してくれて結構だ。ただ、文字列自体は、こちら側で工夫してあげないといけない。「立ち読み」を検索するなら、戦前の送り仮名などを考えて、「立ち読」「立読」あたりを入力する。
・年代ソート
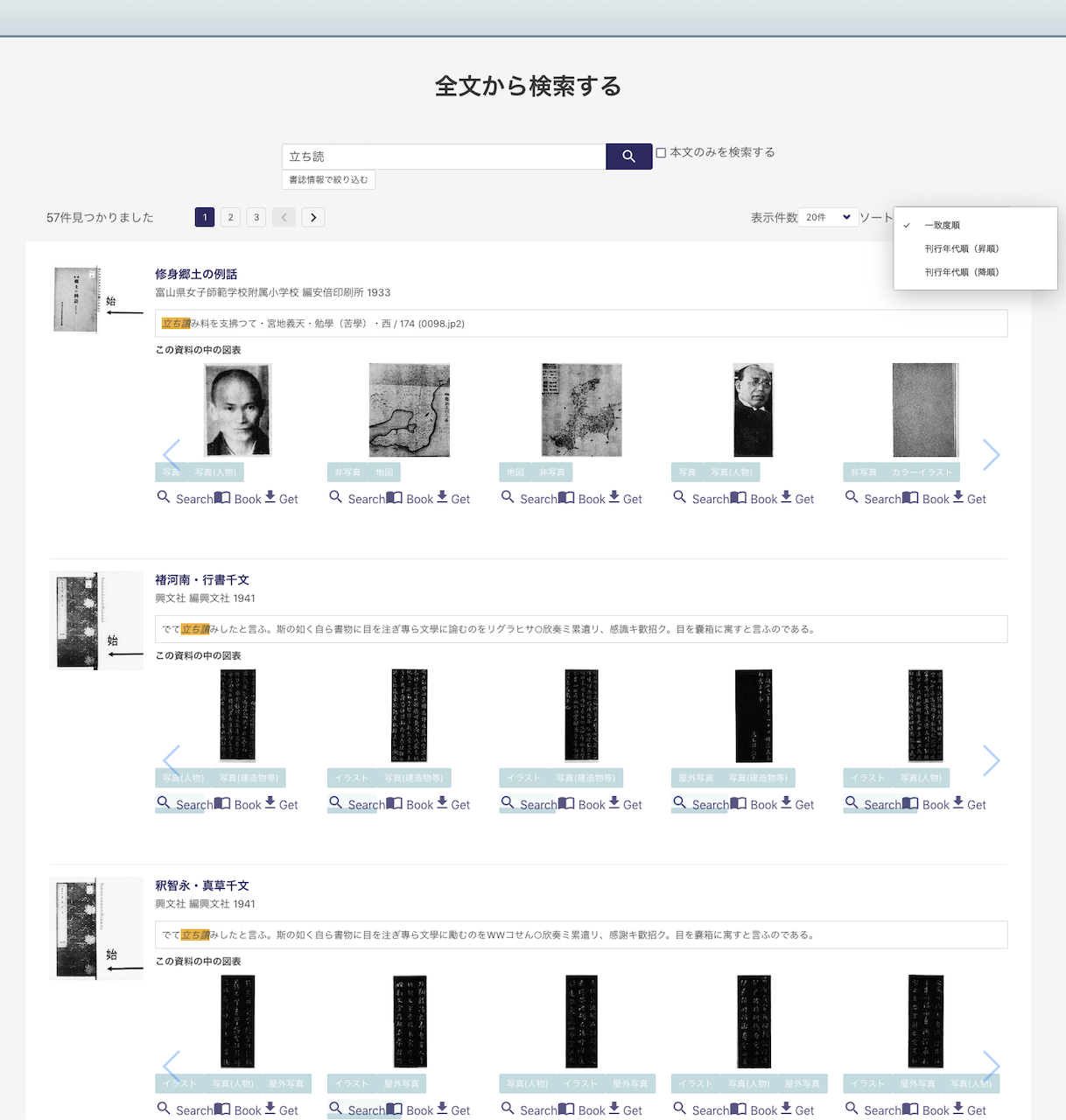
いま試みに「立ち読」で検索すると、57件見つかる。デフォルトの並びが「一致度」なので「刊行年代順(昇順)」に切り替える【図3】。余談だが、なぜ機械屋さんは「一致度」が好きなんだろう? なにをどう重み付けしているのかわからんが、調べ物に不慣れな人たちには、「一致度」も結構かもしらん。しかし、NDLナントカの類を引く人たちは、初手から検索語は「一致」済みのような気がする。ヘビーユーザーをどこまで顧客とみなすかというマーケティング問題だが、私はレファ担当時代、100回中98回は時系列順にソートしなおしていた。
私は歴史的思考をするので、古→新が好きだが、現代人のために、新→古(新しい順;刊行年代降順)でもよい。ともかく、刊行年順しないと、ソート結果の一覧に意味が感じ取られなくなる。
上記「立ち読み」の初出例でも、ソート機能がついたので、すぐに見つかったが、それ以前のない時には別の、後代のものを誤認していた(それでも一応、「研究」だからヒットしたのを全部見たのよ)。
・図3 ソートを切り替える
開発者がネットにいて、年代ソートができないのはいかがか、と書物蔵が言ったら、二三日でつけてくれたようだ。ツギデジは実験サービスでもあるので、官僚機構に似合わずそういった手直しもまだできるのだろう。年代順で気をつけるべきは、年代不明ないし推定年代の本が、昇順だと全部先に表示されることである。年代不明なら「0000」年となって何より先に、元の書誌データで1800年代「[18–]」と推定されていたら「1800」年刊行として並ぶ。これはツギデジのせいではないが(デジコレも同じ)。
・他のコマのテキスト
部分のテキストが左の本文に表示されるのだから、全文もダウンロードできるのでは、と当然考える。右下の「↓この資料の全文テキストデータ」で一応できるが、誤変換や、結局出版物版面と見比べないと使えるレベルにならないので、そうは使わないだろう。むしろ、使っているコマの前後コマのテキストが適宜、表示されてコピペできるような機能が望まれる。ふつうは当該部分の前後を引用して使うものなので。
・ルビ
専門書でない場合、戦前は大抵、ルビ(ふりがな)が出版物に振られていた。それが版面にあるので、ルビも一緒に自動変換されて混在している【図4】。これはルビも検索できるので結構なことなのだが、現状では㌧でいる言葉をつなげているので気をつける。
・図4 「雨戸(あまど)の側(わき)へ立寄(たちよ)り耳(みヽ)を」が「あまどわきたちよみ」になっている。
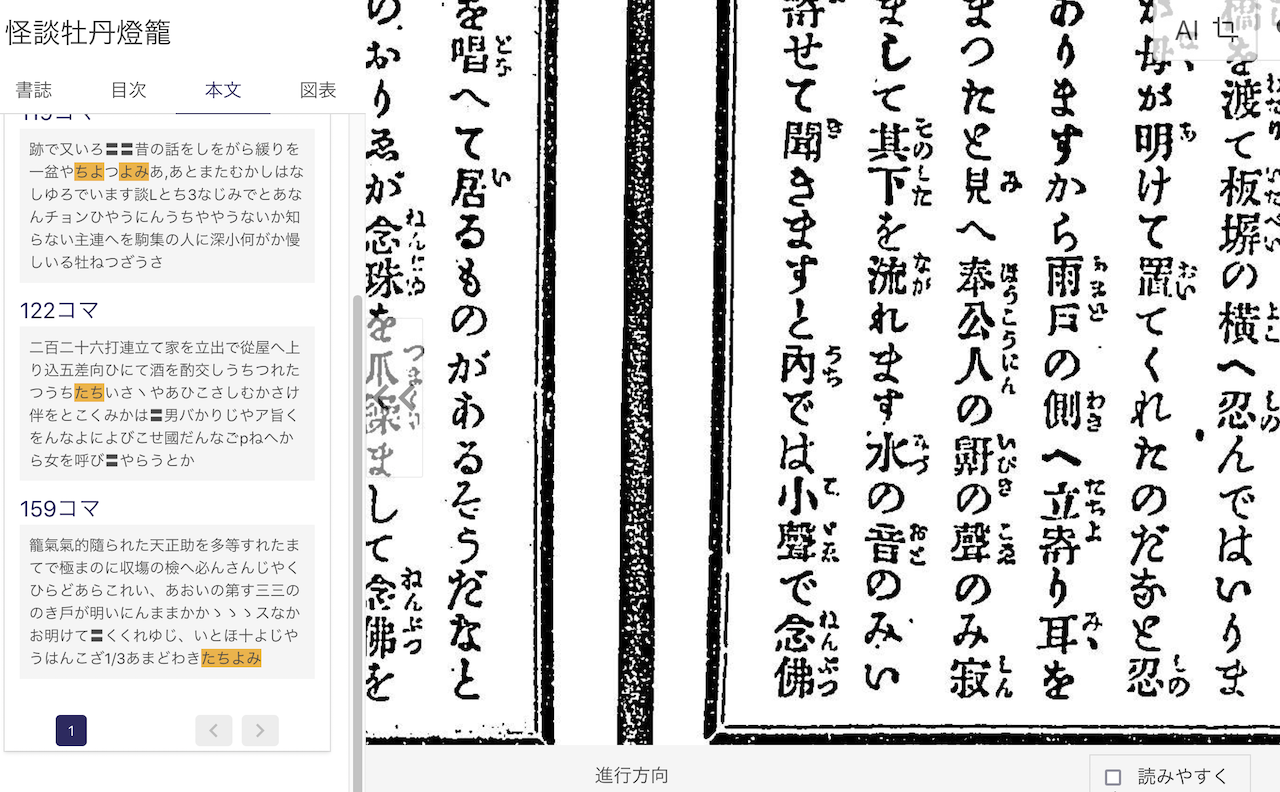
ルビの行を1行とみなして読む発想は悪くないんだが、ぜんぶくっつけちゃうのは、マズい。別の語としてインデックスできないかしら。現状ではノイズが多すぎて使えない。
6.これからの可能性
すでに『日本国語大辞典』に用例が、などと書いたが、あのOEDにも比すべき日国の用例が、全部、かなり繰り上がるのではなかろうか。日国の初出例を誰がメンテするかは版元が考えるべきことかもしれないが。
およそ日本及び日本語を対象とする学問は――多くは人文学や社会科学だろうが――いままでタイトルか、せいぜい目次レベルしか検索できなかったものが、全ジャンルについてざっくりとではあるが、検索できるようになる。もちろん趣味の歴史研究などにもよいだろう。編集業、ライター業にも場合によっては役立つだろう。いわんやリサーチャーにおいておや。NHK総合の『チコちゃんに叱られる!』などの文化史・風俗史のクイズ番組、教養番組がらみならなおさら。
私みたいに一般名詞などを検索するのは、ノイズや、語の選定や語形の検討でそこそこ難しいだろうが、固有名詞ならば、初心者でも結構すぐ役立つだろう。NHK総合『ファミリーヒストリー』や『人名探求バラエティー 日本人のおなまえっ!』などで流行りの先祖調べなどにも使えると思う。
Googleブックスの日本語資料と比べてみると次の表になろう。
・表2 ツギデジ・Googleブックス日本語分の対比
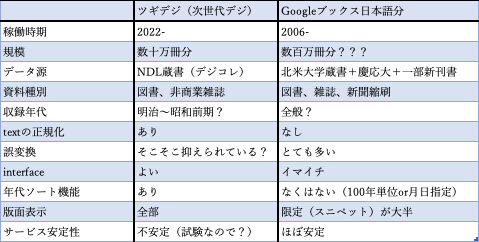
上記対比表はほんとうにざっくりしたもの。栄枯盛衰の激しいIT界で、20年近く開発年代を違うDBを比較するのもなんなのだが。それはともかくDBは刻々と変化しつづけいきなり消えたりする。いま再度ツギデジを固有名詞で引いて結果はどうか――もはやDB評価は結果からしか立論できないではないか――見ようとしたら2月17日14:36現在動いてないのでわからない。しかし、国立図書館の事業なのでいきなり消滅はないだろう。Googleブックスが7、8年まえだかいきなり1週間ほど無反応になった時には、ほんとうに驚いた。上記対比表には本来ならNDLデジコレ全文データ分があるべきだが、去年、使おうとして使えないレベルだったので使わないままになっている(ので載せていない)。
この連載第4回でも言ったが、Googleブックス日本語分はかなり使いづらく、かつ版面はNDLで現物を参照する必要が大半だったので、それに対してNDLツギデジは、検索機能も一応のレベルに達し、なにより版面が全部出るので有り難い。
7.余談:画像検索について
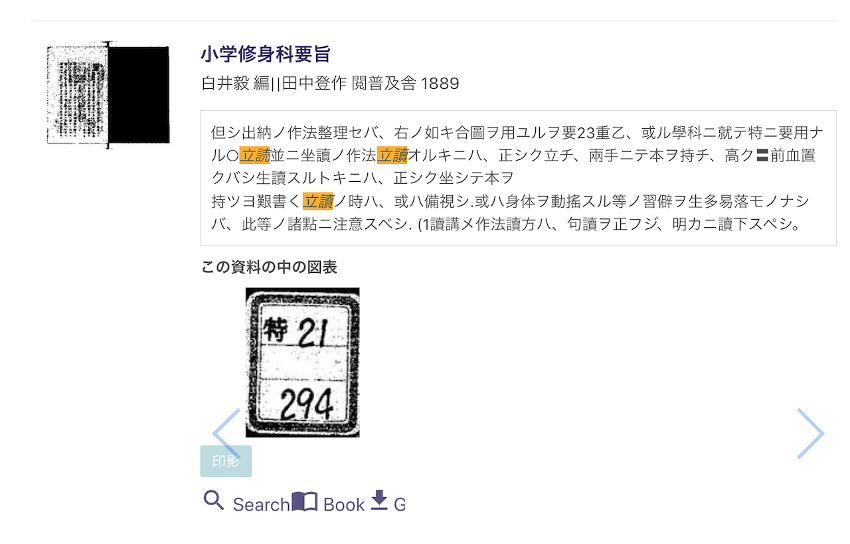
ツギデジにはGoogleイメージのような画像検索機能があるが、図版のない本が多い搭載データ群のせいか、インデックスづけのせいか、あまり使えない。そこで単なる余談を展開するが、次の本のラベル【図5】を書いたのは図書閲覧課時代の私(1992-1995)だ。当時は几帳面な字を書いていたものである。請求記号「特21」は明治期乙部という資料群にあたり、これが当時請求された(=利用された)際に私がラベルをヒラの右肩に貼ったのであろう。デジコレは背文字を撮影しなかったので背ラベルは出ないはずであるから。このように補修その他で後代のラベルが貼付されることがある。ラベルと請求記号(及び受入登録印)からその個体の来歴を調べる、ということも、ここ十年ほど質問が増えたのでよくした。
・図5 『小学修身科要旨』の「この中の図表」にラベルが表示される。テキストは「坐読(ざどく)」に対して、先生指名で立って教科書を読むことを「立読(りつどく)」という例。
8.ちょっとした思いつき――官報が全文DB化されたなら
外野だからあえて言う。連載第五回「明治期からの新聞記事を「合理的に」ざっと調べる方法」を書いて気づいたのだが、せっかくデジコレに搭載されている戦前官報の記事がほとんど目次に採録されていない。釈迦に説法だが戦前の官報コンテンツは今の官報というよりも、社説のない新聞紙そのものであった。ゆえにこれらを全文DB化すると、1883(明治16)年から1952(昭和27)年までの官製新聞DBが、あっという間にできてしまう。明治〜昭和前期の新聞記事を「合理的に」検索できる手段は、まだまだ少ない。一方でNDLの新館地下書庫にある何十万ではきかない号数の新聞紙群が、あれが全部撮影され、なおかつインデクシングされるのはいつになるかわからない。政策的なことを言えば、大手新聞社から文句がこない官製新聞紙DBが、すぐできるところに転がっているのだ。
技術的なことを言えば、インデクシングにせよ全文DB化にせよ、新聞紙デジ化で隘路となる段組、段ヌキ、ヘッドラインの処理が、官報ではずっと単純ということもある。
■次回予告
索引の排列(よみ、ローマ字、電話帳式 letter by letter word by wordなど)のパターン分けについて。おまけで冊子索引を作る際、最大の難所のこと。
* 実際に、レベル3の項目レベルの文字列を採録しDB化、レファ本化することを柱とすることで何十人もの正職員を何十年間も養い続けてきたDB会社が現にある、って日外アソシエーツのことだが、社史がない。日本図書館史の上からもあるべきかと。
小林昌樹(図書館情報学研究者)
1967年東京生まれ。1992年国立国会図書館入館。2005年からレファレンス業務。2021年に退官し慶應義塾大学文学部講師。専門はレファレンス論のほか、図書館史、出版史、読書史。共著に『公共図書館の冒険』(みすず書房)ほかがあり、『レファレンスと図書館』(皓星社)には大串夏身氏との対談を収める。詳しくはリサーチマップ(https://researchmap.jp/shomotsu/)を参照のこと。
☆本連載は皓星社メールマガジンにて配信しております。
月一回配信予定でございます。ご登録はこちらよりお申し込みください。
また、テーマのリクエストも随時募集しております。「〇〇というDBはどうやって使えばいいの?」「△△について知りたいが、そもそもどうやって調べれば分からない」など、皓星社Twitterアカウント(@koseisha_edit)までお送りください。